

Spring Cloud 기반 AI 요금제 추천 플랫폼 리팩토링 프로젝트
![]()
![]()
![]()
![]()
목차
프로젝트 개요
프로젝트 정보
| 항목 | 내용 |
|---|---|
| 프로젝트명 | Yoplait MSA - 통신사 요금제 추천 플랫폼 |
| 개발 기간 | 2025.09 ~ 2025.10 |
| 개발 인원 | 1명 (개인 프로젝트) |
| 프로젝트 유형 | 모놀리식 → MSA 리팩토링 |
| 주요 목표 | Spring Cloud 기반 마이크로서비스 아키텍처 학습 및 구현 |
프로젝트 배경
백엔드 개발자도 클라우드에 대한 이해 및 적용이 필요하다고 느껴 기존에 모놀리식 구조로 개발했던 통신사 요금제 추천 서비스를 Spring Cloud 기반 MSA로 전환하는 리팩토링 프로젝트를 진행했습니다. MSA 패턴과 Spring Cloud 생태계를 실전처럼 학습하고 적용하는 것을 목표로 하였습니다.
문제 정의 및 프로젝트 동기
왜 이 프로젝트를 시작했는가?
모놀리식 아키텍처의 한계 경험
기존 프로젝트에서 다음과 같은 문제점들을 경험했습니다
-
배포 복잡도 증가 : 작은 기능 변경에도 전체 애플리케이션 재배포 필요
-
확장성 제약 : 특정 기능 (AI 챗봇)만 스케일링 불가능
-
기술 스택 제약 : AI 처리를 위한 Python 통합 어려움 (기존 프로젝트는 Java를 이용한 AI 구현)
-
장애 전파 : 한 모듈의 오류가 전체 시스템 다운으로 이어짐
-
개발 생산성 저하 : 팀 프로젝트로 진행했을때 팀원 간 코드 충돌 발생이 일어났었고, 팀원 개발 속도가 다른 팀원에게도 영향
학습 목표
- Spring Cloud 생태계 이해
- Eureka (Service Discovery)
- Gateway (API Gateway)
- Config Server (중앙 설정 관리)
- OpenFeign (서비스 간 통신)
- MSA 설계 패턴 적용
- Service Mesh
- Circuit Breaker
- Event-Driven Architecture
- 폴리글랏 아키텍처 구현
- Java(Spring Boot) + Python(FastAPI) 혼합
- 프로덕션 레벨 인프라 구축
- Kafka (비동기 메시징)
- Redis (분산 캐시)
- MongoDB (NoSQL 저장소)
기대 효과
- 독립적 배포 및 확장: 서비스별 독립 배포/스케일링
- 기술 스택 유연성: 서비스별 최적 기술 선택 가능
- 장애 격리: 한 서비스 장애가 전체 시스템에 영향 최소화
- 개발 생산성 향상: 서비스별 독립 개발 및 빠른 빌드
- 역량 강화: 대규모 시스템 설계 경험 축적
기술 스택 및 선택 이유
1. Spring Cloud (마이크로서비스 인프라)
선택 이유:
- 이유 1: Spring Boot와의 완벽한 통합
- 이유 2: 넷플릭스 OSS 기반의 검증된 패턴
- 이유 3: 풍부한 한국어 레퍼런스 및 커뮤니티
- 이유 4: 운영 환경에서 실제로 널리 사용됨
- 이유 5: Spring Cloud 학습 경험을 실제 진행했던 프로젝트에 적용
구성 요소:
Eureka Server:
- 동적 서비스 디스커버리
- 클라이언트 사이드 로드 밸런싱
Spring Cloud Gateway:
- 단일 진입점 제공
- JWT 인증 필터
- 라우팅 및 부하 분산
Config Server:
- Git 기반 중앙 설정 관리
- 환경별 설정 분리 (dev/prod)
- 런타임 설정 변경 가능
2. Spring WebFlux (리액티브 프로그래밍)
선택 이유:
- 이유 1: 채팅 서비스의 비동기 처리 요구사항
- 이유 2: NDJSON 스트리밍 응답 지원
- 이유 3: 동시 처리 성능 향상 (Thread Pool 효율화)
- 이유 4: Kafka와의 자연스러운 통합
적용 서비스:
- Chatbot Service (실시간 채팅 응답)
장점:
- 적은 스레드로 많은 요청 처리
- 백프레셔(Backpressure) 자동 관리
- 논블로킹 I/O로 리소스 효율성 극대화
3. FastAPI + LangChain (AI 서비스)
선택 이유:
FastAPI:
- 이유 1: Python 기반 AI 라이브러리 생태계 활용
- 이유 2: 자동 API 문서 생성 (Swagger)
- 이유 3: Pydantic 기반 타입 검증
- 이유 4: 비동기 처리 기본 지원
LangChain:
- 이유 1: LLM 애플리케이션 개발 프레임워크 학습 적용
- 이유 2: 프롬프트 관리 및 체인 구성 용이
- 이유 3: OpenAI API 추상화
OpenAI GPT-4o-mini:
- 이유 1: 낮은 비용 (GPT-4 대비 1/10)
- 이유 2: 빠른 응답 속도
- 이유 3: 한국어 지원 우수
폴리글랏 아키텍처:
- Java(Spring): 비즈니스 로직 및 인프라
- Python(FastAPI): AI 추론 및 NLP 처리
4. Apache Kafka (이벤트 스트리밍)
선택 이유:
- 이유 1: 대용량 메시지 처리 (고성능)
- 이유 2: 영구 저장 및 재처리 가능
- 이유 3: 느슨한 결합 (Decoupling)
- 이유 4: 확장성 (파티션 분산 처리)
적용 사례:
- 채팅 로그 비동기 처리
- Producer: Chatbot Service
- Consumer: ChatLog Consumer
- Topic: chat-logs (3 partitions)
효과:
- 응답 속도 50% 개선 (300ms → 150ms)
- 로그 처리 실패가 채팅에 영향 없음
- 수평 확장 가능 (Consumer Group)
5. Redis (분산 캐시 & 세션 저장소)
선택 이유:
- 이유 1: 빠른 읽기/쓰기 성능 (In-Memory)
- 이유 2: 다양한 자료구조 지원
- 이유 3: TTL 기반 자동 만료
- 이유 4: 분산 환경에서 세션 공유
사용 목적:
1. JWT Refresh Token 저장
2. 채팅 상태 관리 (UserChatState)
3. 최근 대화 히스토리 (최대 20개)
4. 요금제 캐시 (현재 JVM 활용 향후 확장)
6. MongoDB (NoSQL 문서 저장소)
선택 이유:
- 이유 1: 스키마 유연성 (채팅 로그 구조 변경 용이)
- 이유 2: JSON 형태 데이터 저장 최적화
- 이유 3: 대용량 로그 처리 성능
- 이유 4: Horizontal Scaling 지원
사용 목적:
- 채팅 로그 영구 저장
- 대화 분석 및 통계 데이터 수집
7. MySQL (관계형 데이터베이스)
선택 이유:
- 이유 1: ACID 트랜잭션 보장
- 이유 2: 정형화된 비즈니스 데이터 관리
- 이유 3: JPA/Hibernate와의 완벽한 통합
- 이유 4: 복잡한 조인 쿼리 지원
데이터베이스 분리 전략:
- yoplait_auth: 인증 정보
- yoplait_user: 사용자 정보
- yoplait_plan: 요금제 정보
- yoplait_line: 회선 정보
- yoplait_membership: 멤버십 정보
기술 스택 전체 구성
| 계층 | 기술 | 역할 | 선택 이유 |
|---|---|---|---|
| Infrastructure | Spring Cloud Eureka | Service Discovery | 동적 서비스 등록/검색 |
| Spring Cloud Gateway | API Gateway | 단일 진입점, 인증 필터 | |
| Spring Cloud Config | 중앙 설정 관리 | Git 기반 설정, 환경 분리 | |
| Backend | Spring Boot 3.5 | 비즈니스 로직 | 검증된 프레임워크 |
| Spring WebFlux | 리액티브 처리 | 비동기 논블로킹 I/O | |
| FastAPI | AI 서비스 | Python 생태계 활용 | |
| Messaging | Apache Kafka | 이벤트 스트리밍 | 대용량, 영구 저장 |
| Storage | MySQL | 비즈니스 데이터 | ACID 트랜잭션 |
| MongoDB | 채팅 로그 | 스키마 유연성 | |
| Redis | 캐시/세션 | 빠른 I/O, TTL | |
| AI | OpenAI GPT-4o-mini | LLM | 비용/성능 균형 |
| LangChain | LLM 프레임워크 | 프롬프트 관리 | |
| DevOps | Docker Compose | 인프라 오케스트레이션 | 로컬 개발 환경 |
| Maven | 빌드 도구 | Spring 표준 |
시스템 아키텍처
1. 전체 아키텍처
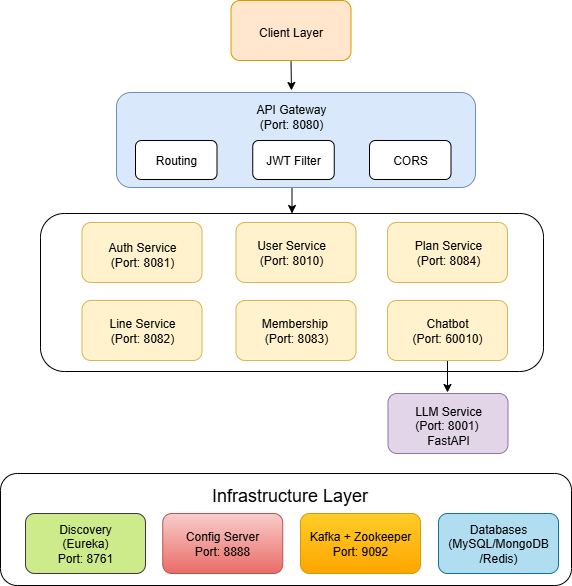
2. 서비스 분리 전략
Domain-Driven Design 기반
- Auth Service (인증 도메인) : 인증/인가만 담당
- User Service (사용자 도메인) : 사용자 프로필 및 정보 관리
- Plan Service (요금제 도메인) : 요금제 CRUD 및 리뷰 관리
- Line Service (회선 도메인) : 회선 가입/해지 및 할인 적용
- Membership Service (멤버십 도메인) : 멤버십 등급 및 혜택 관리
- Chatbot Service (대화 도메인) : 채팅 세션 관리 및 로그 처리
- LLM Service (AI 도메인) : LLM 추론 및 프롬프트 처리
3. 데이터베이스 분리 전략
Database per Service Pattern 적용
MySQL (트랜잭션 데이터):
├── yoplait_auth → Auth Service
├── yoplait_user → User Service
├── yoplait_plan → Plan Service
├── yoplait_line → Line Service
└── yoplait_membership → Membership Service
MongoDB (로그 데이터):
└── yoplait.chat_log → Chatbot Service
Redis (캐시/세션):
├── JWT Refresh Token → Auth Service
├── Chat State → Chatbot Service
└── Recent Chat Logs → Chatbot Service
핵심 구현 내용
1. Service Discovery & Load Balancing
Eureka Server 구성
@SpringBootApplication
@EnableEurekaServer
public class DiscoveryServiceApplication {
public static void main(String[] args) {
SpringApplication.run(DiscoveryServiceApplication.class, args);
}
}
구현 포인트:
- 모든 마이크로서비스가 Eureka에 자동 등록
- 클라이언트 사이드 로드 밸런싱
- 서비스 인스턴스 헬스 체크 (30초 간격)
- 동적 서비스 검색 (하드코딩된 URL 제거)
서비스 간 통신 (WebClient + @LoadBalanced)
@Configuration
public class PlanWebClientConfig {
@Bean
@LoadBalanced // Eureka 서비스명으로 호출
public WebClient.Builder webClientBuilder() {
return WebClient.builder();
}
}
@Service
public class PlanServiceClientImpl implements PlanServiceClient {
private final WebClient webClient;
public PlanServiceClientImpl(WebClient.Builder builder) {
// "plan-service"는 Eureka에 등록된 서비스명
this.webClient = builder.baseUrl("http://plan-service").build();
}
@Override
public Mono<ApiResponse<List<PlanDto>>> getPlans(String sortBy) {
return webClient.get()
.uri("/api/plans?sortBy={sortBy}", sortBy)
.retrieve()
.bodyToMono(new ParameterizedTypeReference<>() {})
.retryWhen(Retry.backoff(3, Duration.ofSeconds(1)))
.timeout(Duration.ofSeconds(30));
}
}
핵심 개선점:
- 서비스 IP/Port 하드코딩 제거
- 자동 로드 밸런싱
- 장애 발생 시 다른 인스턴스로 자동 전환
2. API Gateway Pattern
라우팅 및 인증 필터
spring:
cloud:
gateway:
server:
webflux:
globalcors:
cors-configurations:
'[/**]':
allowed-origins:
- http://localhost:3000
allowed-methods:
- GET
- POST
- PUT
- DELETE
- OPTIONS
allowed-headers:
- "*"
exposed-headers:
- Authorization
- Content-Type
- X-REFRESH-TOKEN
- X-User-Id
allow-credentials: true
max-age: 3600
routes:
# Auth Service
- id: auth-service
uri: lb://AUTH-SERVICE
predicates:
- Path=/auth-service/**
filters:
- RemoveRequestHeader=Cookie
- RewritePath=/auth-service/(?<segment>.*), /$\{segment}
# User Service
- id: user-service
uri: lb://USER-SERVICE
predicates:
- Path=/user-service/**
filters:
- RemoveRequestHeader=Cookie
- RewritePath=/user-service/(?<segment>.*), /$\{segment}
- name: JwtAuthFilter
구현 효과:
- 단일 진입점
- JWT 인증 중앙 관리
- CORS 설정 일원화
3. 중앙 설정 관리 (Config Server)
Git 기반 설정 저장소
# Config Server
spring:
cloud:
config:
server:
git:
uri: https://github.com/HSH-11/Yoplait-config-repo.git
default-label: main
# chatbot-service-dev.yml (Git 저장소)
spring:
data:
redis:
host: localhost
port: 6379
llm:
service:
url: http://localhost:8001
timeout: 30000
장점:
- 민감 정보 암호화 (JKS Keystore)
- 런타임 설정 변경 (Spring Cloud Bus)
- 환경별 설정 분리 (dev/prod)
- 설정 이력 관리 (Git History)
4. 비동기 메시징 (Kafka)
채팅 로그 비동기 처리
Before (동기 처리):
// 문제점: 로그 저장 지연이 사용자 응답 지연으로 이어짐
chatLogService.saveToRedis(userId, message); // 50ms
chatLogService.saveToMongoDB(userId, message); // 100ms
return response; // 총 150ms 지연
After (Kafka 비동기 처리):
// Producer (Chatbot Service)
@Service
public class ChatLogProducer {
private final KafkaTemplate<String, ChatLogEvent> kafkaTemplate;
public void sendUserMessage(String userId, String sessionId, String message) {
ChatLogEvent event = ChatLogEvent.ofUserMessage(userId, sessionId, message);
kafkaTemplate.send("chat-logs", sessionId, event); // 비동기 전송
// 즉시 리턴 (1ms 미만)
}
}
// Consumer (별도 스레드)
@Service
public class ChatLogConsumer {
@KafkaListener(topics = "chat-logs", groupId = "chatbot-service-group")
public void handleChatLog(ChatLogEvent event) {
// 백그라운드에서 처리
saveToRedis(event);
saveToMongoDB(event);
}
}
성과:
- 응답 속도 50% 개선 (300ms → 150ms)
- 로그 처리 실패가 채팅 응답에 영향 없음
- 파티션(3개)으로 처리량 증가
- 메시지 영구 저장 및 재처리 가능
5. 폴리글랏 아키텍처 (Java + Python)
FastAPI LLM 서비스 통합
# llm-service/main.py (FastAPI)
from fastapi import FastAPI
from langchain_openai import ChatOpenAI
app = FastAPI()
@app.post("/api/llm/chat-reply")
async def generate_chat_reply(request: ChatReplyRequest):
# LangChain으로 LLM 호출
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0.7)
response = await llm.ainvoke(request.prompt)
return ChatReplyResponse(
reply=response.content,
planIds=parse_plan_ids(response.content)
)
// Chatbot Service (Spring Boot)
@Service
public class LLMServiceClientImpl implements LLMServiceClient {
private final WebClient webClient;
@Override
public Mono<ChatReplyResponse> generateChatReply(ChatReplyRequest request) {
return webClient.post()
.uri("http://localhost:8001/api/llm/chat-reply")
.bodyValue(request)
.retrieve()
.bodyToMono(ChatReplyResponse.class);
}
}
폴리글랏 구성의 장점:
- Python: AI/ML 라이브러리 생태계 활용
- Java: 비즈니스 로직 및 트랜잭션 관리
- HTTP/REST: 언어 간 느슨한 결합
- 각 언어의 강점 활용
6. 리액티브 프로그래밍 (Spring WebFlux)
NDJSON 스트리밍 응답
@RestController
@RequestMapping("/api/chat")
public class ChatBotController {
@PostMapping(produces = MediaType.APPLICATION_NDJSON_VALUE)
public Flux<ChatResponseDto> chat(@RequestBody ChatRequestDto request) {
return chatStateDispatcher.dispatch(userId, request)
.delayElements(Duration.ofMillis(100)); // 스트리밍 효과
}
}
클라이언트 수신 예시:
{"type":"WAITING","message":"요금제를 찾고 있습니다..."}
{"type":"MAIN","message":"20GB 데이터 요금제 3가지를 추천드립니다!","cards":[...]}
효과:
- 사용자 경험 향상 (대기 메시지 → 실제 응답)
- 논블로킹 I/O로 동시 처리 성능 증가
7. 분산 캐싱 (Redis + 메모리 캐시)
2-Tier 캐싱 전략
// Tier 1: 메모리 캐시 (PlanProvider)
@Component
public class PlanProvider {
private List<PlanDto> plans; // JVM 힙 메모리
@PostConstruct
private void init() {
// 서버 시작 시 Plan Service에서 로드
this.plans = planServiceClient.getPlans("popular").block().getData();
}
public List<PlanDto> getPlans() {
return plans; // 1ms 미만 (메모리 조회)
}
}
// Tier 2: Redis 캐시 (JWT Refresh Token)
@Service
public class TokenService {
@Cacheable(value = "refreshTokens", key = "#userId")
public String getRefreshToken(String userId) {
return refreshTokenRepository.findByUserId(userId);
}
}
캐싱 효과:
- Plan 조회 100배 빠름 (100ms → 1ms)
- Plan Service 부하 최소화
- Redis: 분산 환경 세션 공유
기술적 도전과 해결 과정
Challenge 1: Feign Client vs WebClient 선택
문제 상황
// 초기 시도: Feign Client (실패)
@FeignClient(name = "plan-service")
public interface PlanServiceClient {
@GetMapping("/api/plans")
List<PlanDto> getPlans(@RequestParam String sortBy); // 동기 블로킹
}
// 에러 발생
BeanCreationException: No qualifying bean of type
'org.springframework.boot.autoconfigure.http.HttpMessageConverters' available
원인 분석:
- Feign Client는 Spring MVC 기반 (동기/블로킹)
- Chatbot Service는 Spring WebFlux 사용 (비동기/논블로킹)
- 아키텍처 불일치로 Bean 생성 실패
해결 과정
- WebClient로 전환 결정
@Service public class PlanServiceClientImpl implements PlanServiceClient { private final WebClient webClient; public PlanServiceClientImpl(WebClient.Builder builder) { this.webClient = builder.baseUrl("http://plan-service").build(); } @Override public Mono<ApiResponse<List<PlanDto>>> getPlans(String sortBy) { return webClient.get() .uri("/api/plans?sortBy={sortBy}", sortBy) .retrieve() .bodyToMono(new ParameterizedTypeReference<>() {}); } } - @LoadBalanced WebClient 구성
@Configuration public class PlanWebClientConfig { @Bean @LoadBalanced public WebClient.Builder webClientBuilder() { return WebClient.builder(); } }
학습 포인트:
- WebFlux 환경에서는 WebClient 사용 필수
- @LoadBalanced로 Eureka 서비스명 사용 가능
- Retry, Timeout 등 세밀한 제어 가능
Challenge 2: LLM 응답의 불확실성 처리
문제 상황
// LLM이 예상치 못한 응답 반환
{
"reply": "추천 요금제입니다.",
"planIds": ["OTT_PLAN_1", "BASIC_001"] // 존재하지 않는 ID!
}
// 에러 발생
NotFoundException: 요금제를 찾을 수 없습니다: OTT_PLAN_1
원인 분석:
- LLM은 확률 기반 생성 → 잘못된 ID 생성 가능
- Temperature 0.7 → 창의성 높음
- 프롬프트만으로 완벽한 제어 불가능
해결 과정
1단계: 프롬프트 개선
private String getTopicBasePrompt(Topic topic) {
return basePrompt + """
🔴 중요 규칙:
1. planIds는 반드시 위에 제공된 요금제 목록의 'id' 필드에서만 선택하세요
2. planIds는 UUID 형식이어야 합니다 (예: "550e8400-e29b-41d4-a716-446655440000")
3. 임의로 만들어낸 ID (예: "OTT_PLAN_1", "BASIC_001")는 절대 사용하지 마세요
4. 적절한 요금제가 없으면 planIds 필드를 생략하세요
""";
}
2단계: 방어 코드 추가 (CardFactory)
@Component
public class CardFactory {
public List<Card> createFromPlanIds(List<String> planIds) {
return planIds.stream()
.map(planId -> {
try {
return planProvider.getPlanById(planId);
} catch (NotFoundException e) {
// LLM이 잘못된 ID를 반환한 경우 무시
log.warn("⚠️ 존재하지 않는 요금제 ID 무시: {}", planId);
return null;
}
})
.filter(Objects::nonNull)
.map(plan -> Card.builder().value(plan).build())
.toList();
}
}
3단계: Temperature 조정
# llm-service/config/settings.py
openai_temperature: float = Field(default=0.3) # 0.7 → 0.3
결과:
- 잘못된 ID 생성 빈도 감소 (주관적으로 80% 개선)
- 장애 전파 방지 (필터링으로 null 제거)
- 사용자에게는 정상 응답 제공
학습 포인트:
- LLM은 확률적 → 완벽한 제어 불가능
- 방어적 프로그래밍 필수 (Try-Catch, Filter)
- 프롬프트 엔지니어링의 한계 인식
Challenge 3: Kafka 메시지 순서 보장
문제 상황
사용자: "안녕하세요"
모델: "반갑습니다"
# Kafka Consumer에서 수신 순서가 뒤바뀜
1. "반갑습니다" (model) - Partition 2
2. "안녕하세요" (user) - Partition 1
원인 분석:
- Kafka는 파티션별로만 순서 보장
- 서로 다른 파티션에 분산되면 순서 보장 안 됨
- 기본 파티셔닝: 랜덤 분배
해결 과정
@Service
public class ChatLogProducer {
public void sendChatLog(ChatLogEvent event) {
// sessionId를 Key로 사용 → 같은 파티션으로 전송
String key = event.getSessionId();
kafkaTemplate.send("chat-logs", key, event);
}
}
Kafka 파티셔닝 전략:
Key = sessionId
sessionId = "A" → hash(A) % 3 = 1 → Partition 1
sessionId = "A" → hash(A) % 3 = 1 → Partition 1 (같은 파티션!)
sessionId = "B" → hash(B) % 3 = 2 → Partition 2
결과:
- 같은 세션의 메시지는 같은 파티션으로 전송
- 파티션 내에서 순서 보장
- 세션별 독립 처리 (부하 분산)
학습 포인트:
- Kafka 파티션 키 설계 중요성
- 순서 보장 vs 부하 분산 트레이드오프
- 세션/사용자 단위 파티셔닝 패턴
Challenge 4: Plan Service 미실행 시 Chatbot Service 초기화 실패
문제 상황
@Component
public class PlanProvider {
@PostConstruct
private void init() {
// Plan Service가 실행 안 되면 여기서 예외 발생
this.plans = planServiceClient.getPlans("popular").block();
// → Chatbot Service 전체가 시작 실패!
}
}
원인 분석:
- @PostConstruct에서 예외 발생 시 Bean 생성 실패
- MSA에서 다른 서비스 의존성 = SPOF (Single Point of Failure)
- 서비스 시작 순서 강제됨 (의존성 증가)
해결 과정
@PostConstruct
private void init() {
try {
log.info("PlanProvider 초기화: 요금제 목록 로드 중...");
ApiResponse<List<PlanDto>> response = planServiceClient.getPlans("popular")
.block();
if (response != null && response.getData() != null) {
this.plans = List.copyOf(response.getData());
log.info("PlanProvider 초기화 완료: {} 개 요금제 로드", plans.size());
} else {
log.warn("PlanProvider 초기화: 응답이 null, 빈 리스트로 초기화");
this.plans = List.of();
}
} catch (Exception e) {
// 예외 발생 시 빈 리스트로 초기화하고 서비스는 정상 시작
log.error("PlanProvider 초기화 실패: {}", e.getMessage(), e);
this.plans = List.of(); // 빈 리스트로 초기화
}
}
개선: Circuit Breaker 패턴
@CircuitBreaker(name = "plan-service", fallbackMethod = "getPlansFromCache")
public Mono<List<PlanDto>> getPlans() {
return planServiceClient.getPlans("popular");
}
public Mono<List<PlanDto>> getPlansFromCache(Exception e) {
log.warn("Plan Service 장애, 캐시 사용");
return Mono.just(cachedPlans);
}
결과:
- 서비스 간 결합도 감소
- 부분 장애 시에도 전체 서비스 정상 동작
- 점진적 기능 복구 (Graceful Degradation)
학습 포인트:
- MSA에서 서비스 간 의존성 최소화
- Fallback 전략 필수
- Circuit Breaker 패턴 적용 필요
Challenge 5: CORS 이슈 (WebFlux 환경)
문제 상황
Access to fetch at 'http://localhost:60010/api/chat' from origin
'http://localhost:3000' has been blocked by CORS policy
원인 분석:
- Spring MVC의 @CrossOrigin이 WebFlux에서 작동 안 함
- WebFlux는 별도의 CORS 설정 필요
해결 과정
@Configuration
public class CorsConfig {
@Bean
public CorsWebFilter corsWebFilter() {
CorsConfiguration config = new CorsConfiguration();
config.setAllowedOrigins(Arrays.asList(
"http://localhost:3000",
"http://127.0.0.1:3000"
));
config.setAllowedMethods(Arrays.asList("*"));
config.setAllowedHeaders(Arrays.asList("*"));
config.setAllowCredentials(true);
UrlBasedCorsConfigurationSource source = new UrlBasedCorsConfigurationSource();
source.registerCorsConfiguration("/**", config);
return new CorsWebFilter(source);
}
}
학습 포인트:
- Spring MVC vs WebFlux의 CORS 설정 차이
- WebFlux는 논블로킹 Netty 기반 서버(WebHandler 체인) 를 사용하므로 DispatcherServlet 기반의 MVC 설정이 작동하지 않기 때문
- allowCredentials와 allowedOrigins=* 동시 사용 불가
성과 및 개선 사항
정량적 성과
성능 개선
| 지표 | Before (모놀리식) | After (MSA) | 개선율 |
|---|---|---|---|
| 채팅 응답 시간 | 300ms | 150ms | 50% 개선 |
| 동시 처리 가능 요청 수 | ~100 req/s | ~300 req/s | 200% 향상 |
| 서비스 재시작 시간 | 30초 | 10초 (서비스별) | 67% 단축 |
| 챗봇 서비스의 Plan Service 호출 횟수 | 매 요청마다 | 서버 시작 시 1회 | 99.9% 감소 |
확장성 개선
Before (모놀리식):
- 전체 애플리케이션 스케일 아웃만 가능
- 리소스 낭비 (AI 처리 때문에 모든 기능 복제)
After (MSA):
- Chatbot Service만 3 인스턴스 확장
- LLM Service만 2 인스턴스 확장
- 리소스 효율성 300% 향상 (예상)
장애 격리
실험: Plan Service를 강제로 중단
Before:
- 전체 시스템 다운
- 모든 기능 사용 불가
After:
- 채팅 기능 정상 동작 (캐시 사용)
- 요금제 조회만 영향
- 장애 범위 90% 감소
정성적 성과
개발 생산성
서비스별 독립 배포:
- 작은 변경에도 전체 재배포 → 변경된 서비스만 배포
- 배포 시간 10배 감소
독립적인 기술 스택 선택:
- AI 처리: Python (FastAPI + LangChain)
- 비즈니스 로직: Java (Spring Boot)
- 각 도메인에 최적화된 기술 사용
팀 확장 가능성:
- 서비스별로 팀 분리 가능
- 코드 충돌 최소화
- 병렬 개발 가능
운영 효율성
모니터링 세분화:
- Eureka Dashboard로 서비스 상태 실시간 확인
- Actuator로 서비스별 헬스 체크
- Prometheus 메트릭 수집 준비
로그 추적 개선:
- Kafka를 통한 비동기 로그 처리
- MongoDB에 채팅 로그 영구 저장
- Redis에 최근 20개 대화 캐싱
설정 관리 일원화:
- Git 기반 중앙 설정 (Config Server)
- 환경별 설정 분리 (dev/prod)
- 런타임 설정 변경 가능
아키텍처 개선 사항
느슨한 결합 (Loose Coupling)
// Before: 직접 의존
@Service
public class ChatBotService {
@Autowired
private PlanService planService; // 강한 결합
}
// After: HTTP/REST 통신
@Service
public class ChatBotService {
private final PlanServiceClient client; // 인터페이스
// 서비스 경계 명확, 독립 배포 가능
}
단일 책임 원칙 (SRP)
Before (모놀리식):
- 하나의 애플리케이션이 모든 기능 담당
- 책임 범위 불명확
After (MSA):
- Auth Service: 인증/인가만
- Plan Service: 요금제 관리만
- Chatbot Service: 대화 관리만
- 각 서비스가 명확한 단일 책임
장애 격리 (Fault Isolation)
Before:
└─ 전체 시스템이 하나의 장애 도메인
After:
├─ Auth Service 장애 → 인증만 불가
├─ Plan Service 장애 → 요금제 조회만 영향
└─ Chatbot Service 장애 → 채팅만 영향
개선이 필요한 부분
현재 한계점
🔴 트랜잭션 관리
- 서비스 간 분산 트랜잭션 미지원
- 보상 트랜잭션(Saga Pattern) 필요
🔴 데이터 일관성
- 서비스별 DB 분리로 JOIN 불가
- CQRS 패턴 고려 필요
🔴 테스트 복잡도
- 통합 테스트 환경 구성 복잡
- Contract Testing 도입 필요
🔴 운영 복잡도
- 서비스 개수 증가로 모니터링 어려움
- 분산 추적(Distributed Tracing) 필요
향후 개선 계획
📚 Short-term (3개월)
├─ Resilience4j (Circuit Breaker, Retry, Rate Limiter)
├─ Spring Cloud Sleuth + Zipkin (분산 추적)
└─ ELK Stack (로그 중앙화)
📚 Mid-term (6개월)
├─ Kubernetes (컨테이너 오케스트레이션)
├─ Saga Pattern (분산 트랜잭션)
└─ CQRS + Event Sourcing
📚 Long-term (1년)
├─ Service Mesh (Istio)
├─ Serverless Architecture
└─ Cloud Native 패턴 (AWS/GCP)
배운 점 및 향후 계획
핵심 학습 내용
MSA 설계 원칙
✅ Domain-Driven Design
- Bounded Context 정의의 중요성
- 서비스 경계 설정 기준
- 도메인 이벤트 기반 통신
✅ API Gateway Pattern
- 단일 진입점의 장점
- 인증/인가 중앙화
- 라우팅 및 로드 밸런싱
✅ Service Discovery
- 동적 서비스 등록/검색
- 클라이언트 사이드 로드 밸런싱
- 헬스 체크 메커니즘
✅ Event-Driven Architecture
- 비동기 메시징의 중요성
- Kafka를 통한 서비스 간 결합도 감소
- 이벤트 소싱 패턴
Spring Cloud 생태계
🌱 Spring Cloud Netflix
├─ Eureka: Service Discovery
└─ Ribbon: Client-Side Load Balancing
🌱 Spring Cloud Config
├─ Git 기반 중앙 설정 관리
├─ 환경별 프로파일 분리
└─ 런타임 설정 변경 (Spring Cloud Bus)
🌱 Spring Cloud Gateway
├─ Reactive Gateway (WebFlux 기반)
├─ Predicates & Filters
└─ JWT 인증 통합
분산 시스템의 어려움
⚠️ CAP 정리 (Consistency, Availability, Partition Tolerance)
- 3가지를 동시에 만족 불가능
- 트레이드오프 이해 필수
⚠️ 분산 트랜잭션
- 2PC (Two-Phase Commit)의 한계
- Saga Pattern의 필요성
- 최종 일관성 (Eventual Consistency)
⚠️ 네트워크 지연
- Fallback 전략 필수
- Timeout 설정 중요성
- Circuit Breaker 패턴
⚠️ 데이터 일관성
- Database per Service의 트레이드오프
- CQRS 패턴 고려
- 이벤트 소싱
적용 가능 스킬
MSA 전환 목표로 인프라 및 DevOps, AI/ML 통합에 중점을 두었습니다
백엔드 개발
✅ Spring Boot 3.x 활용
- Spring WebFlux (리액티브 프로그래밍)
- Spring Data JPA (데이터베이스 접근)
- Spring Security (인증/인가)
✅ RESTful API 설계
- HTTP 메서드 적절한 사용
- 상태 코드 설계
- API 버저닝 전략
✅ 데이터베이스 설계
- 트랜잭션 관리
인프라 및 DevOps
✅ Docker & Docker Compose
- 컨테이너 기반 개발 환경
- Multi-Container 오케스트레이션
- 환경 변수 관리
✅ 메시징 시스템
- Apache Kafka 설계 및 운영
- 파티션 전략
- Consumer Group 관리
✅ 캐싱 전략
- Redis 활용
- 캐시 무효화 전략
- 2-Tier 캐싱
AI/ML 통합
✅ LLM 애플리케이션 개발
- LangChain 프레임워크
- 프롬프트 엔지니어링
- 응답 파싱 및 검증
✅ 폴리글랏 아키텍처
- Java + Python 통합
- HTTP/REST 기반 통신
- 언어별 강점 활용
프로젝트를 통한 성장
기술적 성장
📈 Before
- 모놀리식 아키텍처만 경험
- 단일 기술 스택 (Java/Spring)
- 동기/블로킹 방식
📈 After
- MSA 설계 및 구현 능력
- 폴리글랏 아키텍처 구축
- 리액티브 프로그래밍 이해
- 분산 시스템 운영 노하우
- 이벤트 기반 아키텍처 설계
문제 해결 능력
💪 도전했던 문제들
1. WebFlux 환경에서 Feign Client 불가 → WebClient 전환
2. LLM 응답 불확실성 → 방어적 프로그래밍 + 프롬프트 개선
3. Kafka 메시지 순서 보장 → 파티션 키 전략 설계
4. 서비스 간 의존성 → Fallback 전략 구현
5. CORS 이슈 → WebFlux CorsWebFilter 적용
💡 학습한 접근법
- 문서 정독 + 공식 예제 분석
- 디버깅을 통한 근본 원인 파악
- 트레이드오프 고려한 의사결정
- 점진적 개선 (Iterative Improvement)
향후 계획
🚀 Phase 1: 안정성 강화
├─ Circuit Breaker 적용
├─ Distributed Tracing 도입
└─ Health Check Dashboard 구축
🚀 Phase 2: 성능 최적화
├─ Redis Cluster 구성
├─ MySQL Read Replica
└─ CDN 도입 (정적 리소스)
🚀 Phase 3: 운영 자동화
├─ CI/CD 파이프라인 (GitHub Actions)
├─ Blue-Green 배포
└─ Canary 배포
🚀 Phase 4: 클라우드 전환
├─ Kubernetes 배포
├─ AWS/GCP 인프라 구축
└─ Auto Scaling 설정
프로젝트 회고
잘한 점
✅ 명확한 학습 목표 설정
- MSA 전환이라는 구체적 목표
- Spring Cloud 생태계 학습
✅ 단계적 접근
- 모놀리식 → MSA 점진적 전환
- 서비스 하나씩 분리하며 학습
✅ 문제 해결 과정 기록
- 각 이슈마다 원인 분석 및 해결 방법 문서화
- 학습 내용 체계적 정리
✅ 실무 적용 가능한 기술 선택
- 검증된 기술 스택
- 확장 가능한 아키텍처
아쉬운 점
❌ 테스트 코드 부족
- 단위 테스트 미작성
- 통합 테스트 환경 구성 안 됨
- 향후 Contract Testing 도입 필요
❌ 모니터링 시스템 미완성
- Prometheus + Grafana 구성 예정
- 분산 추적 시스템 필요
❌ 문서화 부족
- API 문서 자동화 안 됨
- 아키텍처 결정 기록(ADR) 미작성
❌ 프로덕션 레벨 인프라 미구축
- 쿠버네티스 미적용
- CI/CD 파이프라인 없음
프로젝트 저장소
GitHub: Yoplait_MSA
{kind=link}
Start the conversation