
Consistent Hashing의 원리와 적용 사례
Consistent Hashing이란?
Consistent Hashing(일관된 해싱)은 분산 시스템에서 데이터를 균등하게 분배하기 위한 해싱 기법입니다. 기존의 해싱 방식과 달리, 노드가 추가되거나 제거될 때 전체 데이터의 재배치 부담을 최소화하는 특징이 있습니다.
기존 해싱 방식의 문제
- 일반적인 해싱(Hash(Key) % N)은 노드 개수(N)가 변경되면 대부분의 데이터가 다시 해시되어야 합니다.
- 따라서 키를 적절하게 재배치 하지 않는다면 부하가 몰리게 되고 대규모 캐시 미스가 발생하여 분산 시스템에서 확장성과 가용성을 저하시킬 수 있습니다.
Consistent Hashing의 원리
해시 공간을 균등 분포 해시 함수를 사용해서 0~2^n-1 범위의 원형 링 형태로 구성합니다.
데이터와 노드를 모두 해시하여 이 원형에 배치합니다.
특정 키의 데이터는 자신보다 가장 가까운(시계방향) 노드에 저장됩니다.
새로운 노드가 추가될 경우, 일부 데이터만 이동하면 되므로 부하가 적습니다.
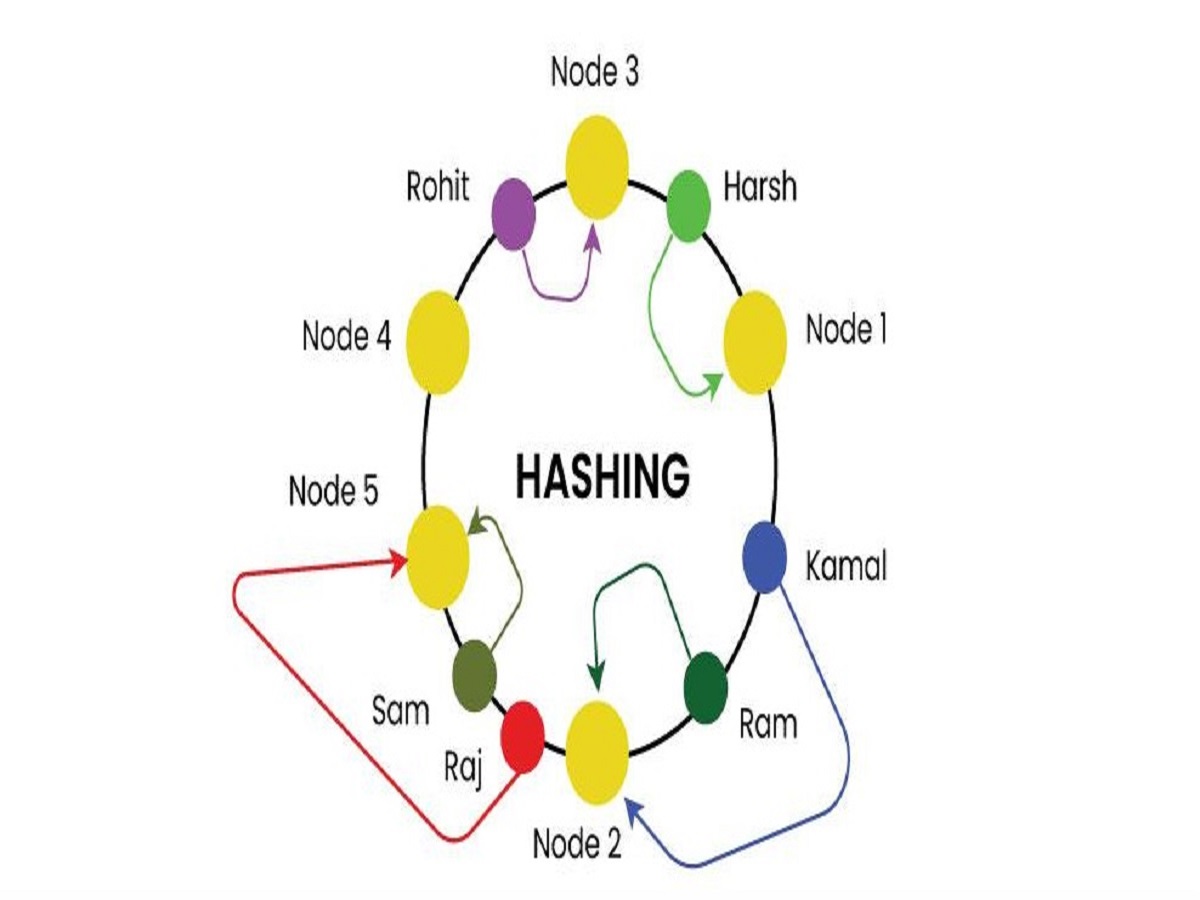
- 서버 추가: 시계방향으로 hash key를 사용했던 기존 1개의 서버만 키가 변경 됩니다. 다른 키는 재배치 X
- 서버 조회: 해당 hash key로부터 시계방향으로 서버를 탐색하여 만난 첫번째 서버를 조회합니다.
- 서버 삭제: 마찬가지로 기존 조회 규칙에 따라 일부 키만 재배치합니다.
이렇게 구현한 안정 해시는 단점이 없을까?
데이터 분포의 비균형: 균등 분포 해시 함수는 이상적으로 모든 파티션에 데이터가 고르게 분배되도록 하지만, 실제로 키의 분포는 완벽하게 균등하지 않을 수 있습니다. 예를 들어, 특정 구간에 많은 키가 몰리거나, 반대로 다른 구간에는 키가 적을 수 있어 비균형 핫스팟을 형성할 수 있습니다.
동적 서버 추가/삭제: 서버가 동적으로 추가되거나 삭제될 때, 해시 분포가 변경되는데 이때 기존에 분배된 데이터가 새로운 서버로 재배치되며, 전체적으로 분포를 균등하게 만드는 것이 어려울 수 있습니다.
🔑 해결책: 가상 노드(virtual node) 사용
실제 서버(노드)를 1:1로 사용하지 않고, 가상의 노드를 만들어서 사용합니다. 서버 1대가 여러개의 가상 노드를 가질 수 있습니다.
- 가상 노드의 개수를 늘림으로서 키의 분포를 균등하게 만들 수 있습니다.
- 노드의 개수가 많을 수록 표준편차가 적어져 더 균등해지겠지만 그만큼 메모리가 필요하고 추가/삭제시 가상노드를 많이 정리해야 해서 트레이드 오프를 고려해야 합니다.
- 참고로 가상 노드의 수는 무한정 늘릴 수 없기 때문에 필요에 따라 전체 노드 수는 줄이고 성능이 좋은 서버가 많은 노드 수를 가져가게끔 구현할 수도 있습니다.
public class ConsistentHashingWithVirtualNodes {
private static final int VIRTUAL_NODES = 3; // 각 실제 노드에 할당할 가상 노드의 수
private TreeMap<Integer, String> circle = new TreeMap<>();
private List<String> nodes = new ArrayList<>();
// 가상 노드 해시 값을 생성하는 함수
private int getHash(String key) {
return key.hashCode();
}
// 원에 노드 추가
public void addNode(String node) {
nodes.add(node);
// 각 실제 노드에 대해 가상 노드 추가
for (int i = 0; i < VIRTUAL_NODES; i++) {
String virtualNode = node + "-VN" + i; // 가상 노드 이름
int hash = getHash(virtualNode);
circle.put(hash, virtualNode);
}
}
// 원에서 노드 삭제
public void removeNode(String node) {
nodes.remove(node);
// 해당 노드에 대응하는 모든 가상 노드 삭제
for (int i = 0; i < VIRTUAL_NODES; i++) {
String virtualNode = node + "-VN" + i;
int hash = getHash(virtualNode);
circle.remove(hash);
}
}
// 데이터를 어떤 노드에 할당할지 결정
public String getNode(String key) {
int hash = getHash(key);
// 원에서 해당 해시 값보다 큰 첫 번째 노드를 찾음
Map.Entry<Integer, String> entry = circle.ceilingEntry(hash);
if (entry == null) {
// 원을 한 바퀴 돌았을 때
entry = circle.firstEntry();
}
return entry.getValue().split("-")[0]; // 가상 노드의 이름에서 실제 노드만 반환
}
이렇게 구성함으로서 아래와 같은 이점을 챙길 수 있습니다.
- 서버 추가/삭제에도 키 매핑 변경이 최소화된다. cache miss 비율을 줄일 수 있다.
- 서버 추가/삭제를 굉장히 많이 하더라도 한쪽으로 몰리지 않고 데이터가 균등하게 분포된다.
- 위 장점으로 수평적 규모 확장이 쉬워지고 hot spot key (한쪽으로 키가 몰리는 현상)을 최소화 할 수 있다.
🍀 이러한 기술들은 실제로 어디에 많이 쓰일까?
아마존 다이나모 데이터베이스(DynamoDB)의 파티셔닝 관련 컴포넌트
- 역할: DynamoDB는 분산형 NoSQL 데이터베이스로, 데이터를 여러 파티션에 분배하여 저장합니다. 이때 안정 해시를 사용하여 데이터의 분포를 균등하게 유지하고, 시스템 확장 시 기존 데이터를 최소한으로 이동시킵니다. 이 방식은 시스템에 새로운 노드가 추가되거나 노드가 제거될 때 데이터 리밸런싱을 최소화하는 데 유리합니다. DynamoDB는 리더가 없는 복제 시스템을 사용하여 모든 노드에서 읽기/쓰기 작업을 할 수 있게 하며, 안정 해시 덕분에 데이터를 효율적으로 분배하고 리밸런싱의 필요성을 줄일 수 있습니다.
아파치 카산드라(Apache Cassandra) 클러스터에서의 데이터 파티셔닝
- 역할: 카산드라는 분산형 데이터베이스로, 데이터를 클러스터 내 여러 노드에 분산시키기 위해 파티셔닝 키를 해싱합니다. 이때 안정 해시를 사용하여 데이터를 균등하게 분배하고, 클러스터 노드의 추가 및 삭제 시 기존 데이터를 최소한으로 재배치합니다. 안정 해시 덕분에 데이터의 이동을 최소화하면서 시스템의 확장성과 고가용성을 지원할 수 있습니다.
디스코드(Discord) 채팅 어플리케이션
- 역할: Discord는 전 세계에 분산된 서버 클러스터를 사용하여 수백만 명의 동시 사용자에게 서비스를 제공합니다. 새로운 유저가 들어오면, 해당 유저를 특정 채널이나 사용자 그룹에 할당해야 하는데, 이때 안정 해시를 사용하여 유저 데이터를 분배합니다. 노드가 추가되거나 삭제될 때 안정 해시를 통해 리밸런싱을 최소화하고, 기존 사용자 데이터를 유지하면서 새로운 사용자에게 적합한 노드를 할당할 수 있습니다.
아카마이(Akamai) CDN
- 역할: 아카마이는 전 세계에 분산된 캐시 서버를 통해 사용자의 요청을 효율적으로 라우팅합니다. 서버가 추가되거나 삭제될 때, 안정 해시를 사용하여 요청을 새로운 서버로 분배하는데, 이를 통해 리밸런싱을 최소화하고 서버 확장 시 사용자에게 끊김 없는 서비스를 제공합니다. 안정 해시를 사용하면 전 세계적으로 트래픽을 효율적으로 분배하면서도 서버 추가/삭제로 인한 영향이 최소화됩니다.
매그래프(Meglev) 네트워크 로드 밸런서
- 역할: Meglev는 구글이 만든 네트워크 로드 밸런서로, 트래픽을 균등하게 분산시키는 역할을 합니다. 이 로드 밸런서는 안정 해시를 사용하여 트래픽을 여러 서버에 고르게 분배하고, 서버가 추가되거나 삭제될 때 트래픽 리밸런싱을 최소화합니다. 안정 해시를 사용하면 로드 밸런서가 서버의 상태를 효율적으로 관리하면서도 트래픽의 불균형을 최소화할 수 있습니다.


{kind=link}
Start the conversation